Release management as a Digital Public Good - what we have learnt so far
After the launch of our first public release of OpenCRVS in June this year, we quickly realised that things had changed for us as a product design and development team.
What's changed for us since going public?
Previously, as we transitioned the software from prototype through the development and testing of Alpha pre-releases, we were free to prioritise the build of new features independently, informed by the business needs of pilot implementation projects in Bangladesh, Zambia and Niue and from the collective input of our Community.
When we released our OpenSource code to the public, we realised that we would now have to balance community feature requests, incidents requiring hotfixes, training and support alongside our internal product roadmap.
Before the release, we could focus on agility and quality assurance for our new features tested against a fresh install. After the release, we had to ensure that we supported a service level appropriate to maintaining and regression testing a previous release. For each change request, we had to consider a migration pathway for system administrators who would be required to implement the upgrade.
For each change request, we now needed to perform a careful analysis to determine if the request required either a modification to our data model or APIs or a change in the country configuration process. If any of these areas were impacted, we realised that we were dealing with what is known in software development as a "breaking change."
Confronting the upgrade challenge head-on
Whenever we encountered a breaking change request, we understood that the upgrade process between the previous version of OpenCRVS and the new version containing the improvement may not be straightforward. At the same time, we knew that there may be useful features, dependency improvements and critical bug fixes that would not be "breaking" that we would want to get into the hands of system administrators quickly. We needed to quickly formulate a strong and adaptive release process.
During our pilot projects, government system administrators were very reluctant to upgrade their software because, traditionally, upgrading has been hard and potentially dangerous. This was an important learning experience for us.
Staying true to our long-term vision to ensure that "... every person on the planet is recognised, protected and provided for from birth", we could not be satisfied with an upgrade process that was difficult or too risky to perform. We knew that it was critical for us to make sure that the OpenCRVS upgrade process was as easy and as automated as possible.
We embarked upon a period of research to compare how other DPGs manage releases, write migration documentation and which tools they use. We combined this research with the best of the private sector processes and shared library OpenSource documentation we have been exposed to personally from our individual experiences as developers.
We needed to design the OpenCRVS release process to integrate the very best-in-class processes from the OpenSource and private enterprise sectors.
Automatic upgrade and simple migration documentation
We reviewed release notes and migration documentation from other DPGs and noticed large variations. While some migration notes thoroughly explained each new feature with a list of commands that could be run step-by-step to migrate the software, other notes were quite minimal. We recognised the helpful database migration scripts provided by DHIS2 using Flyway and MOSIP's detailed instructions and wondered; Could we automate these database migrations further without the need for supporting software? Could we reduce manual steps to an absolute minimum?
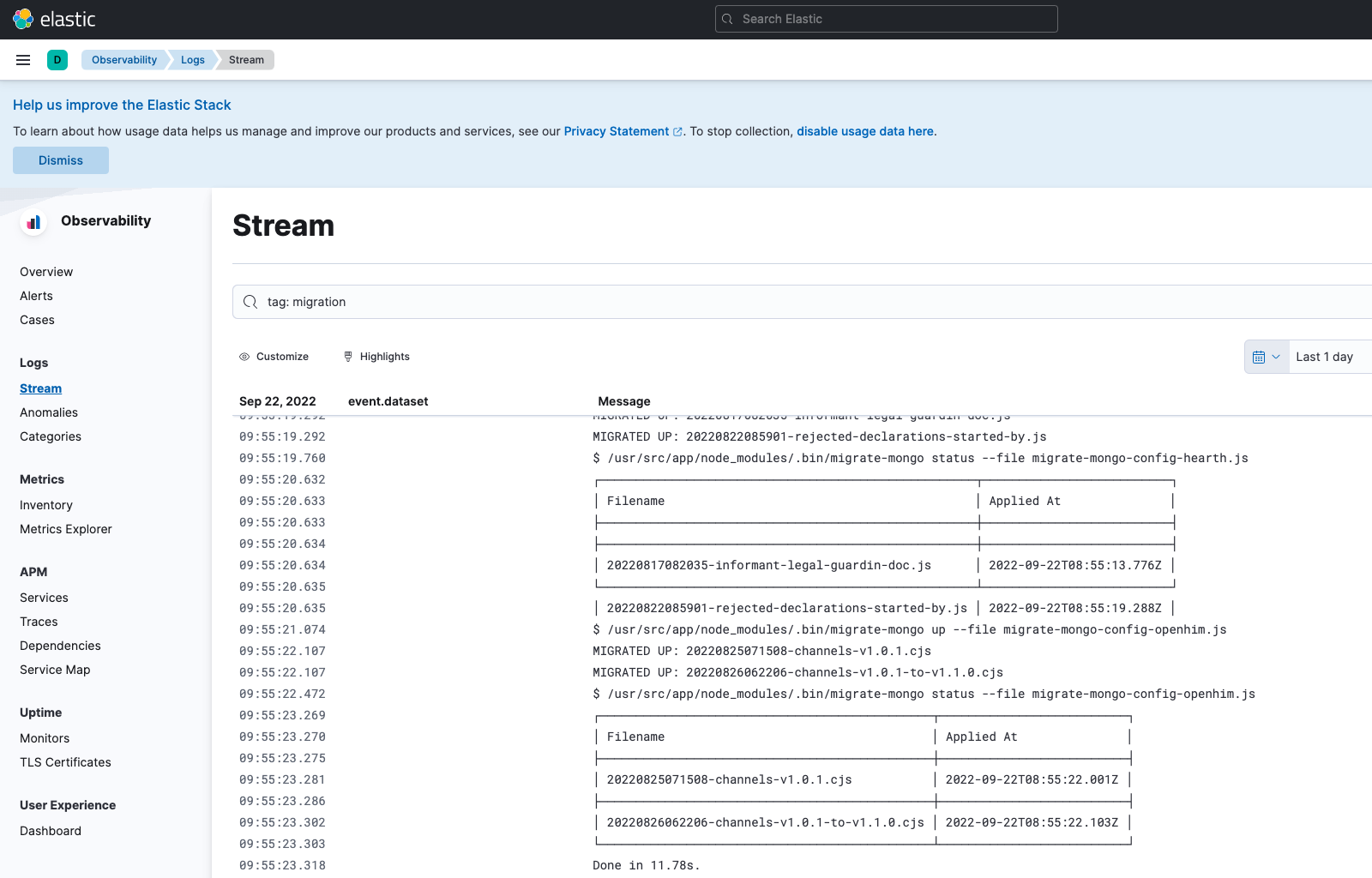
Therefore in today's OpenCRVS release v1.1.0, we have introduced a new microservice to the OpenCRVS stack. Our "migration" service contains all our scripts and automatically detects which migrations have been run previously. It updates OpenCRVS data on its own with no supporting software or intervention required. Additionally, we have extended our Ansible scripts so that with a single command, all infrastructure configuration changes requiring shell scripting automate.
Our migration notes now consist of just 3 steps that need to be run by a system administrator in order to upgrade OpenCRVS. The successful processing of the migrations is visible in Kibana.
Safe releasing: Evolving our development process
Inspired by the approach Spotify took to evolve their development process as they scaled, we decided to merge our Agile Scrum methodology with ITIL Change Management and Incident Management processes. We initiated a Change Advisory Board that meets frequently to classify change requests and hotfixes into semantic release versions and a "release train" of quality assurance.
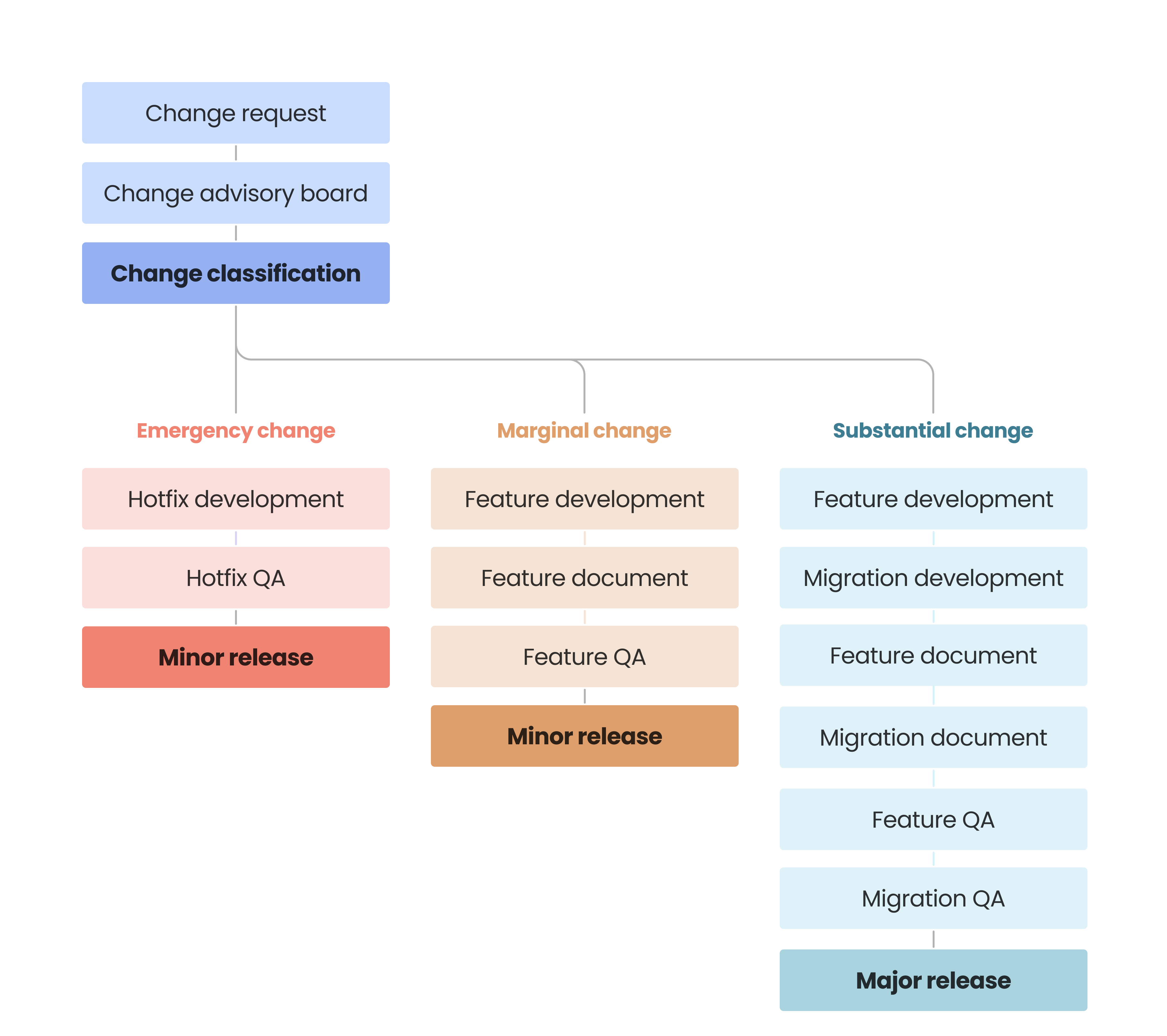
At our subsequent technical planning sessions before our build Sprints, where previously we would work through tasks and test cases to deliver the feature, we now also work through technical tasks to automate the migration. Our QA team defines additional test cases to test the migration automation, and we test documentation to ensure that the migration is easily replicated by our Community.
Our "release train" is enabled by our early adoption of the "Gitflow" branching model, our devops (continuous integration and deployment) and our investment in testing environments.
Safe releasing: Evolving our quality assurance
Our development team has used Gitflow, automated unit and automated end-to-end testing in our CI/CD pipeline for many years. But it was thanks to an invaluable conversation with Petteri Kivimäki (CTO: Nordic Institute for Interoperability Solutions), who showed us how we could standardise our manual QA with Gitflow to make our release process robust.
Petteri showed us how, at X-Road, they had bucketed quality assurance processes into what they referred to as "Quality Gates" at key Gitflow moments that matter. We were running similar automated tests for feature and release branches, and now we knew how to scale these tests with manual QA processes. Thus we are now utilising our limited QA capacity effectively without overburdening them unnecessarily with the maintenance of hotfixes for previous releases.
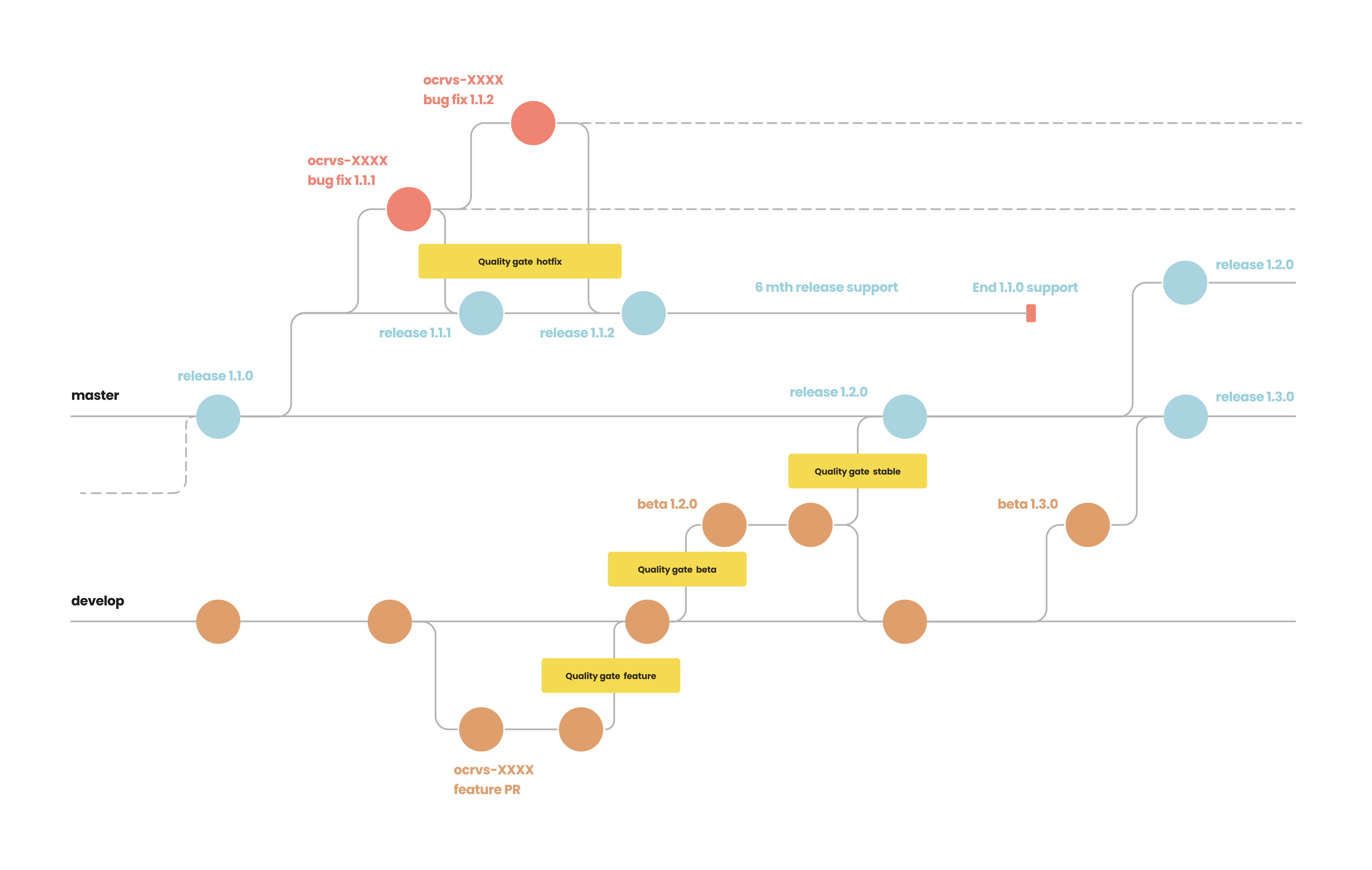
At OpenCRVS, we have adapted X-Road's "Quality Gate" concept (which defines specific gates and QA flows for features, beta releases, stable releases and hotfixes) with our GitHub Action CI/CD pipeline, our dedicated Staging, QA, Configuration and Migration environments and the existing automated tooling that had been so successful for us in the past.
We can now release a minimally tested beta in advance of a stable release, getting features out to our Community faster. We can maintain releases, and our Community knows to what level of testing each semantic version has received. We will continue with our annual 3rd party application and infrastructure penetration test as standard.

Going forward: Maintaining existing releases and scheduling new ones
As a Digital Public Good, it is imperative for us to keep government system administrators and our system implementer community informed of when they can expect new releases and for how long they will receive release support.
OpenCRVS core capacity is limited, so the sharper-eyed of you may have noticed the 6-month support schedule in our Gitflow diagram. This makes our efforts to ensure an automated and easy upgrade procedure a critical process for us to maintain.
We are currently able to schedule substantial releases 3 times per year following the calendar below. We will also be able to issue hotfix releases regularly with our new quality assurance approach. In the future, we intend to extend support of previous releases for up to 12 months or longer, so please look out for announcements on our social channels. You can read more about our versioning approach in our release documentation.

We are whole-heartedly committed to supporting system admins and implementers as they maintain and upgrade OpenCRVS on behalf of governments. If you are upgrading your version of OpenCRVS and have any questions at all, we would love to hear from you. We would also really appreciate your thoughts on this article.
Please get in touch with our technical team in Github discussions or in our online community forum https://community.opencrvs.org. It would be great to hear from you.